 Cloud Financial Management (FinOps)
Cloud Financial Management (FinOps) Autoscaling applications
Autoscaling applications Amazon Web Services
Amazon Web Services Big data
Big data Container infrastructure
Container infrastructure Microsoft Azure
Microsoft Azure Reserved commitment management
Reserved commitment management Cloud services for MSPs
Cloud services for MSPs Google Cloud
Google Cloud Spot Overview
Spot Overview About NetApp
About NetApp Elastigroup
Elastigroup Ocean
Ocean Ocean CD
Ocean CD Eco
Eco Ocean for Apache Spark
Ocean for Apache Spark Spot Security
Spot Security Case Studies
Case Studies Resource Center
Resource Center Documentation
Documentation News
News Service Status
Service Status What Is CloudOps?
What Is CloudOps? How to Operationalize FinOps
How to Operationalize FinOps About Us
About Us Contact Us
Contact Us Careers
Careers
 Reading Time: 5 minutes
Reading Time: 5 minutesIf you’re looking for a high-level introduction about Spark on Kubernetes, check out The Pros And Cons of Running Spark on Kubernetes, and if you’re looking for a deeper technical dive, then read our guide Setting Up, Managing & Monitoring Spark on Kubernetes.
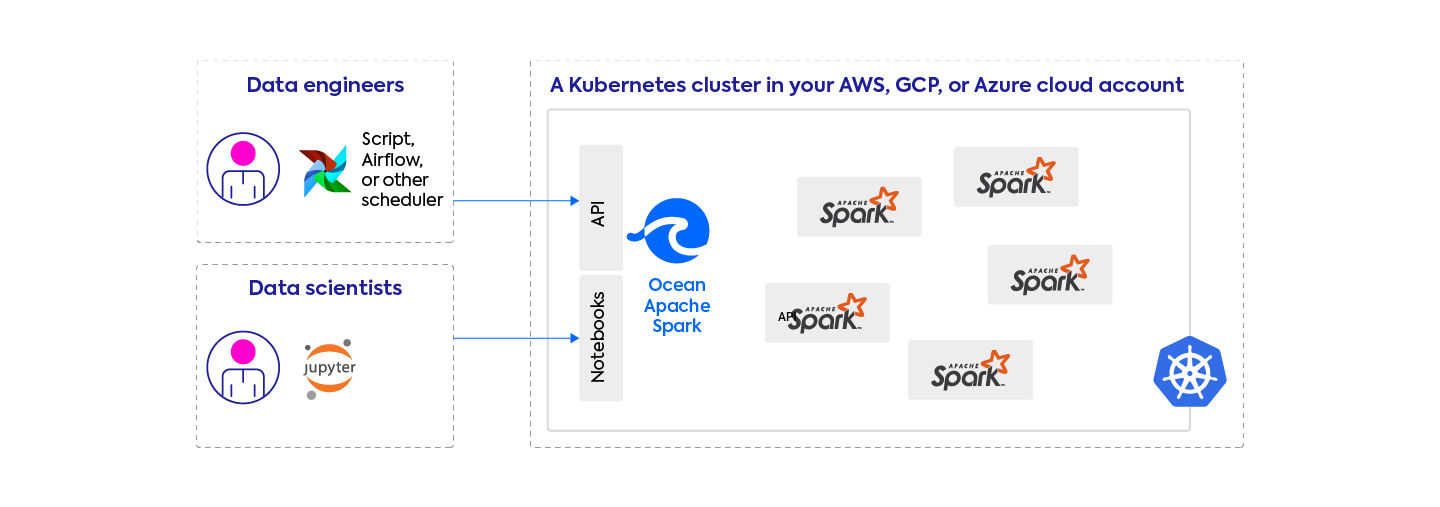
Ocean for Apache Spark is a managed Spark platform deployed on a Kubernetes cluster inside our customers’ cloud account, available on AWS, GCP, and Azure. So our entire product is built on top of Spark on Kubernetes, and we are often asked how we’re different from simply running Spark on Kubernetes open-source.
The short answer is that our platform implements many features which make Spark on Kubernetes much more easy-to-use and cost-effective. By taking care of the setup and the maintenance, our goal is to let you focus on as well as accelerate its adoption and save you a lot of maintenance work. Our goal is to accelerate your data engineering projects by making Spark as simple, flexible and performant as it should be.
Let’s go over our main improvements on top of Spark-on-Kubernetes.
An intuitive user interface
Ocean Spark users get a dashboard where they can view the logs and metrics for each of their Spark applications. They can also access the Spark UI, soon-to-be replaced with our homegrown monitoring tool called Delight (Update, November 20th 2020: First milestone of delight has been released!). The goal of this project is to make it easy for Spark developers to troubleshoot their application when there’s a failure, and to give them high-level recommendations to increase its performance when necessary (for example around data partitioning and memory management).
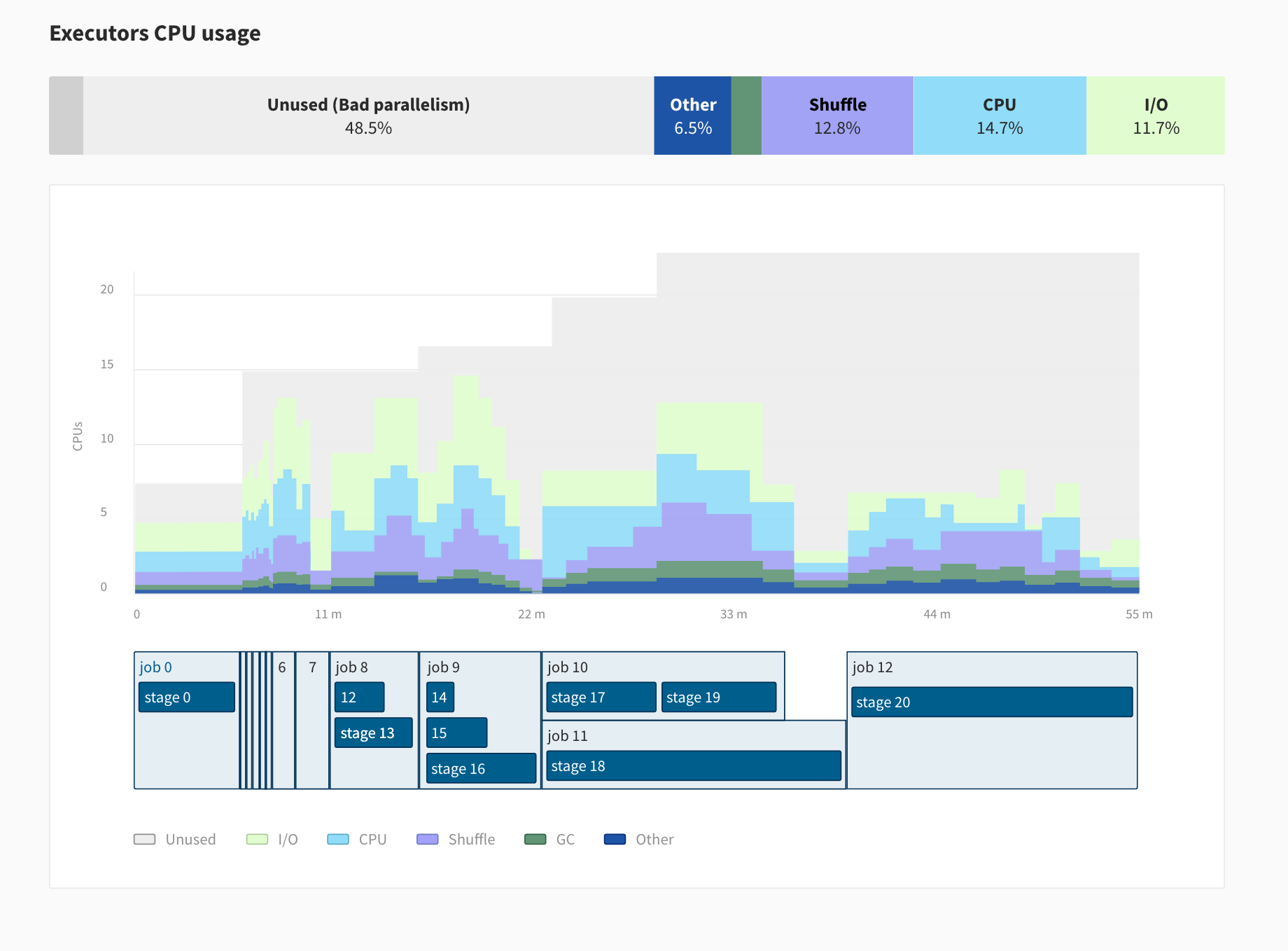
They also have access to a “Jobs UI” which gives a historical graph of your pipelines main metrics like the volume of data processed, the duration, and the costs. So that your team can easily make sure that your production pipelines are running as expected, as well as to track your costs when necessary.
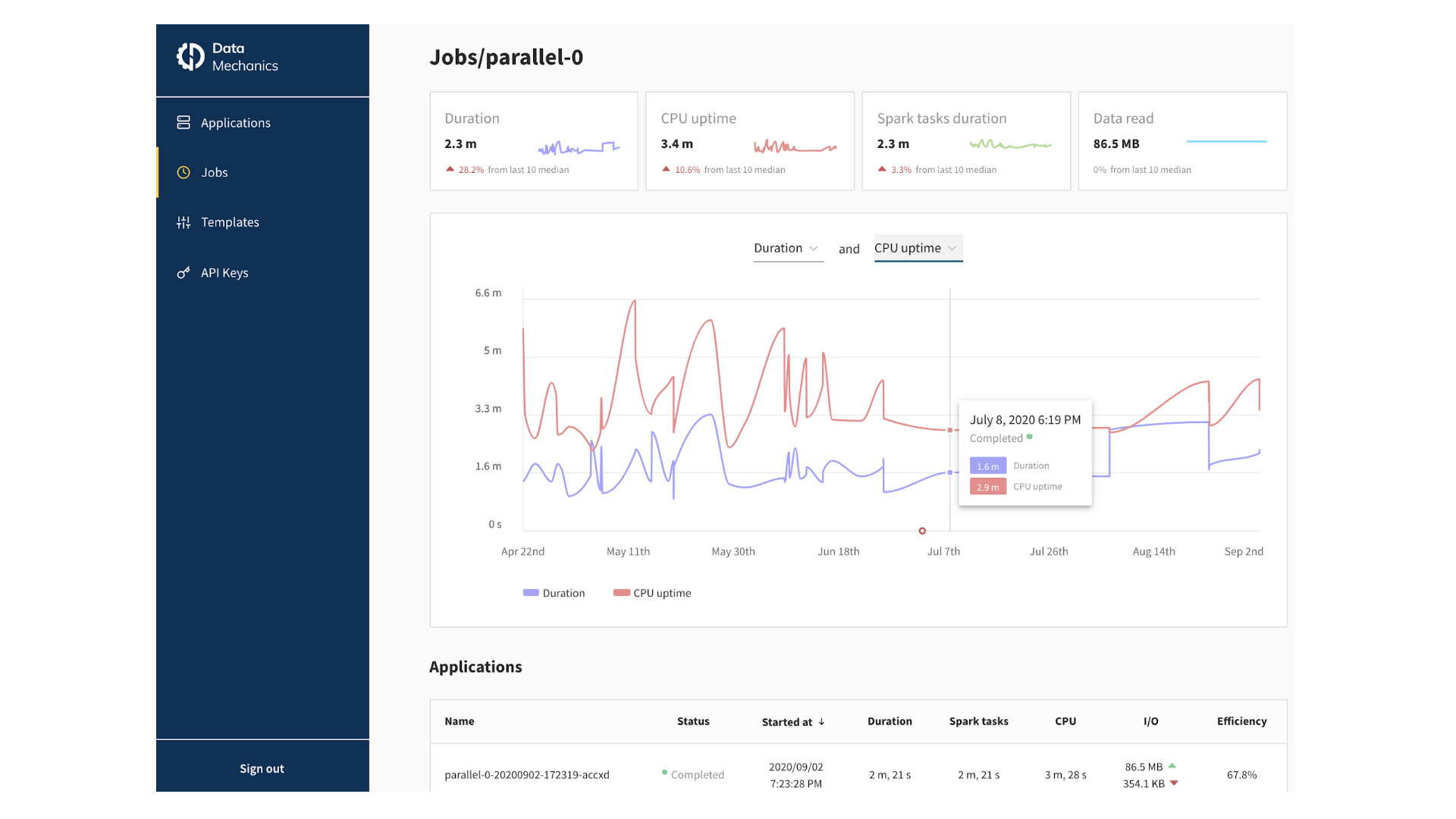
Dynamic optimizations
Ocean for Apache Spark automatically and dynamically optimizes your pipelines infrastructure parameters and Spark configurations to make them fast and stable. Here are the settings that we tune: your pod’s memory and cpu allocations, your disk settings, and your Spark configurations around parallelism, shuffle, and memory management. We do this by analyzing the logs and metrics of your applications, and using the history of the past runs of your applications to find out its bottleneck and optimize it.
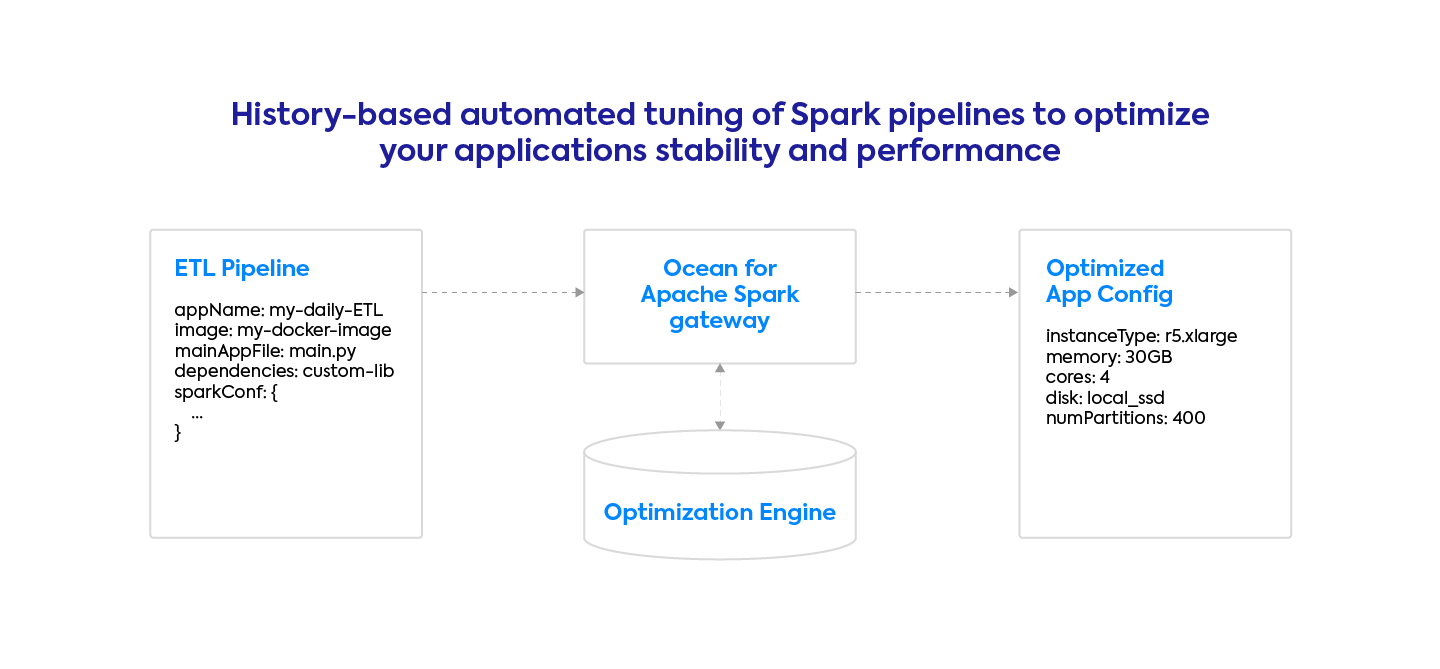
In addition to automated tuning, our platform also implements automated scaling at the level of your Spark application (dynamic allocation) and at the level of the Kubernetes cluster. This means we manage the Kubernetes node pools to scale up the cluster when you need more resources, and scale them down to zero when they’re unnecessary. We also make it easy to use spot nodes for your Spark executors to reduce your cloud costs further.

Last but not least, we offer a fleet of optimized Docker images for Spark which contain optimised connectors to common data sources and sinks. You can either use these images directly, or use them as a base to build your own Docker Images with your custom dependencies. Update (April 2021): These images are publicly available on DockerHub!
The goal of these optimizations is to give you the maximum performance Spark should provide and to reduce your cloud costs. In fact, the management fee that we charge for our services is always compensated (and sometimes by a significant ratio exceeded) by the savings we generate on your cloud provider bill.
Integrations
Data Mechanics has integrations with notebooks services (like Jupyter, JupyterLab, JupyterHub) and scheduler/workflows services (like Airflow).
Since our platform is deployed on a Kubernetes cluster that you have control over, the full ecosystem of Docker/Kubernetes compatible tools is also available to you. And since we’re deployed inside your cloud account, inside your VPC, you can also easily build your own integrations with your home-grown tools inside your company’s network.
The security of a managed service
As a managed service, we take care of the setup and the maintenance of your infrastructure. When you sign up for Data Mechanics, you give us scoped permission on your cloud account, and we use these permissions to create the Kubernetes cluster, keep it up-to-date with the latest security fixes, and push releases with new features every two weeks.
It’s also our responsibility to keep your deployment secure. We can deploy within your company’s VPC and make your cluster private, so that it can only be accessed through your company’s VPN. We give you the tools to apply the security best practices with multiple options for data access and for user authentication (Single Sign On).
Conclusion
We’re proud to build on top, and sometimes contribute to, Spark-on-Kubernetes as well as other open source projects. We’re trying to build the data platform you would build for yourself – in an open and transparent way. By being deployed in your cloud account and in your VPC, you get the flexibility of a home-grown project, and the ease-of-use of a managed platform.
The optimizations we built internally will more than make up for our pricing. In fact many of our customers who migrated to our platform were able to reduce their Spark costs by 70%. If this sounds interesting, why don’t you book a time with our team so we show you how to get started?