
Data Mechanics is a cloud-based Spark platform - an alternative to Databricks, EMR, Dataproc, Azure HDInsight, and so forth - with a focus on making Spark easy-to-use and cost-effective for data engineers. It is deployed on a Kubernetes cluster inside our customers’ cloud account, and adds a lot of features on top of Spark on Kubernetes open source.
But today, we’re not talking about a new feature of our platform.
Today we’re releasing a web-based Spark UI which works on top of any Spark platform, whether it’s on-premise or in the cloud, over Kubernetes or over YARN, with a commercial service or running on open-source Apache Spark.

It consists of a dashboard listing your Spark applications after they have finished running, and a hosted Spark History Server that will back the Spark UI for this application at the click of a button. This project is partially open-sourced, and it is entirely free of charge.
Update (April 2021): Delight has now been officially released!
How Can I Use it?
Create an account on https://delight.datamechanics.co/login.
You should use your company’s Google account if you want to share a single dashboard with your colleagues, or your personal Google account if you want the dashboard to be private to you. As of today, you need a Google account to access our dashboard, but additional sign-in methods will be added in the future. Once your account is created, go under Settings and create a personal access token. This will be needed in the next step.
Attach our open-source agent to your Spark applications.
Follow the instructions on our Github page. We have instructions available for the most common setups of Spark, with instructions for generic spark-submit, and instructions specific to Databricks, EMR, Dataproc, and Spark on Kubernetes using the Spark operator. If you run into an issue, ask us a question, we’ll be happy to help.

Your applications will automatically appear on our dashboard once they complete (successfully or with a failure). Clicking on an application opens up the corresponding Spark UI. That’s it!
How Does It Work? Is It Secure?
This project consists of two parts:
- An open-source Spark agent which runs inside your Spark applications. This agent will stream non-sensitive Spark event logs from your Spark application to our backend.
- A closed-source backend consisting of a real-time logs ingestion pipeline, storage services, a web application, and an authentication layer to make this secure.

The agent collects your Spark applications event logs. This is non-sensitive information about the metadata of your Spark application. For example, for each Spark task there is metadata on memory usage, CPU usage, network traffic (view a sample event log). The agent does not record sensitive information such as the data that your Spark applications actually work on. The agent does not collect your application logs either -- as typically they may contain sensitive information.
This data is encrypted using your personal access token and sent over the internet using the HTTPS protocol. This information is then stored securely inside the Data Mechanics control plane behind an authentication layer. Only you and your colleagues from your Google/GSuite organization will be able to see your application in our dashboard. The collected data will automatically be deleted 30 days after your Spark application completion.
What’s Next?
The release of this free and cross-platform hosted Spark History Server is our first step towards building a Spark UI replacement tool called Data Mechanics Delight. This will be a free and cross-platform Spark UI replacement with new metrics and visualizations that will "delight" you! Our announcement in June 2020 to build a Spark UI replacement had indeed generated a lot of interest from the Spark community. We’re targeting the next release for January 2021.
We know the current release is far from what Delight fans expect, but we hope it will still be valuable to the Spark community, as the Spark History Server is not always easy to set up. More importantly, the current release means we have built most of the base infrastructure of the project -- the Spark agent, a real-time logs collection pipeline, a storage system, an authentication layer and a webapp. We will now gradually add the new screens and visualizations that the community awaits.
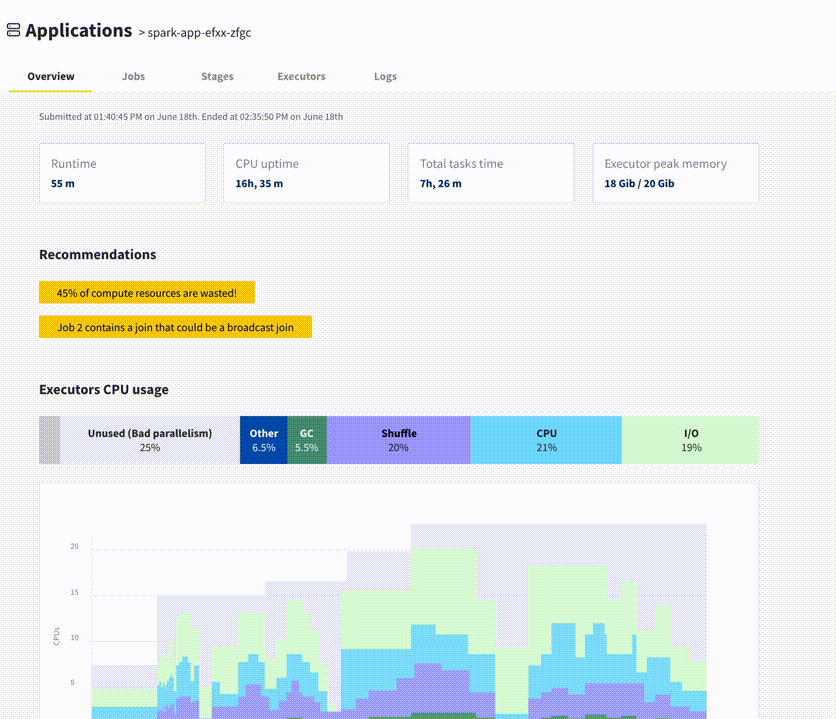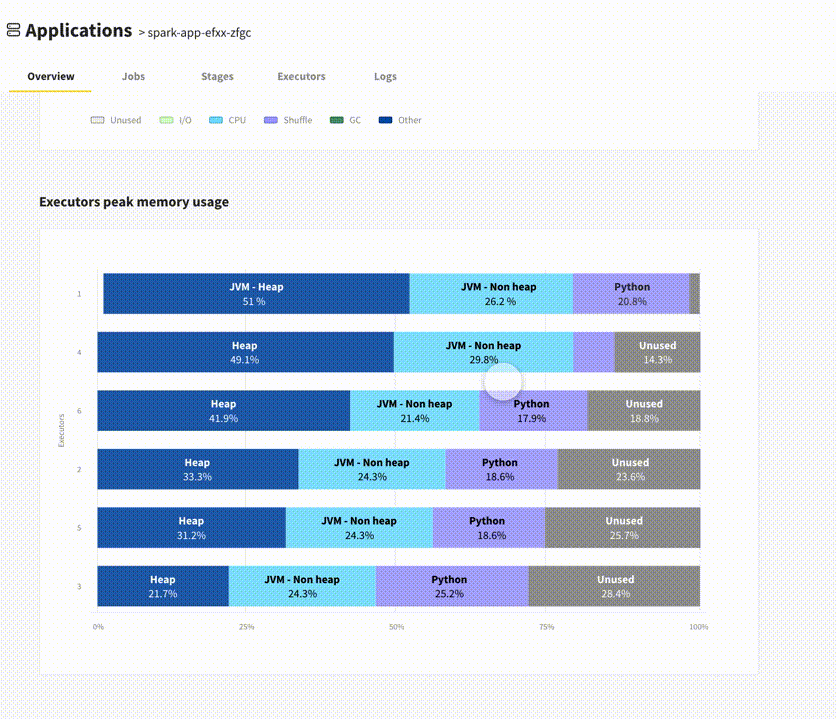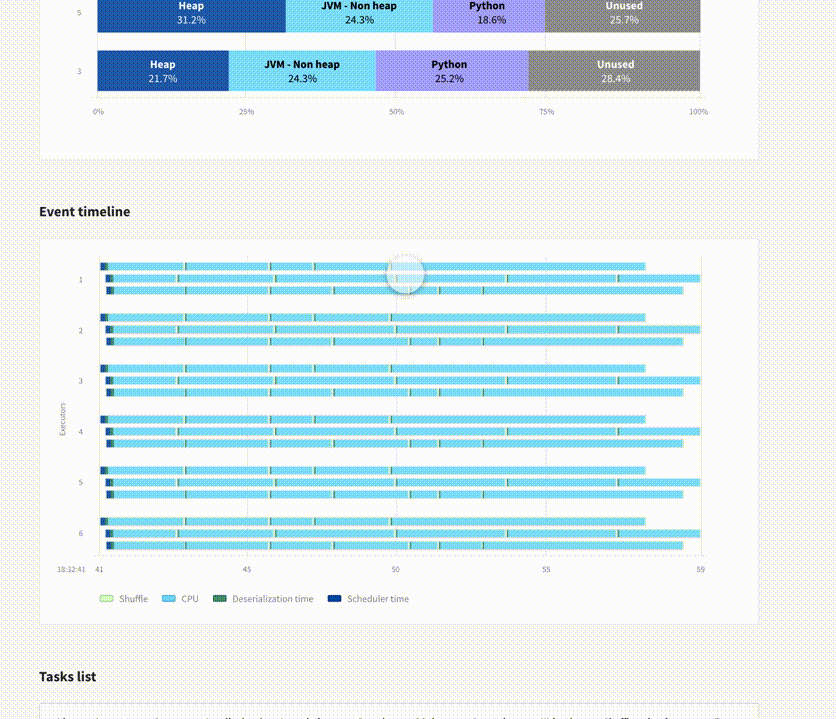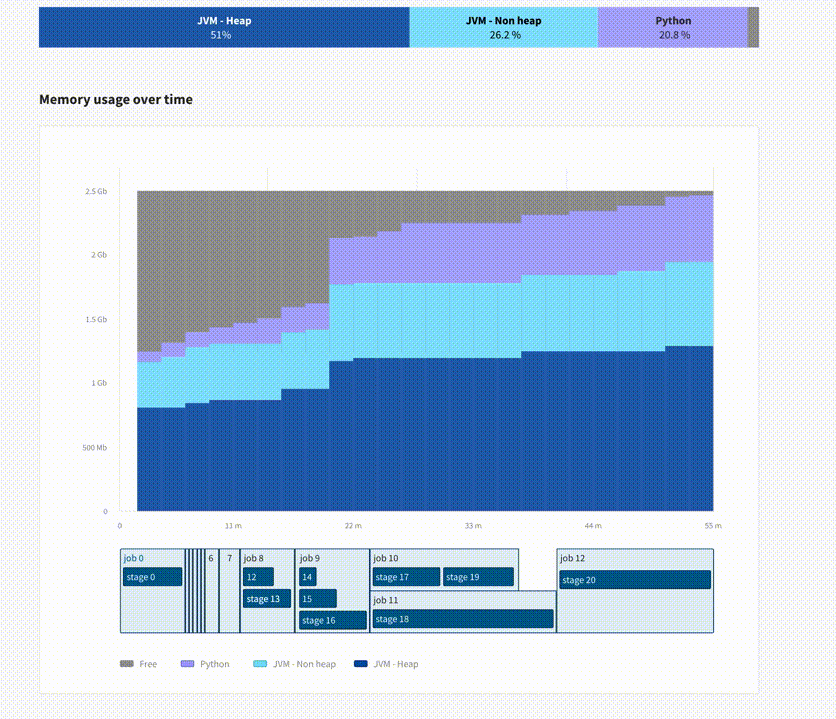
Update (April 2021): Delight has now been officially released! For each Spark application from the dashboard, in addition to giving you access to the Spark UI, it features an overview screen giving you a bird-eye view of your applications’ performance, with CPU & Memory metrics. Try it out and let us know your feedback!
Our mission at Data Mechanics is to make Spark easier-to-use and more cost-effective for data engineering workloads. We hope this tool will contribute to this goal and prove useful to the Spark community. We’d love your feedback about it!

by