 Cloud Financial Management (FinOps)
Cloud Financial Management (FinOps) Autoscaling applications
Autoscaling applications Amazon Web Services
Amazon Web Services Big data
Big data Container infrastructure
Container infrastructure Microsoft Azure
Microsoft Azure Reserved commitment management
Reserved commitment management Cloud services for MSPs
Cloud services for MSPs Google Cloud
Google Cloud Spot Overview
Spot Overview About NetApp
About NetApp Elastigroup
Elastigroup Ocean
Ocean Ocean CD
Ocean CD Eco
Eco Ocean for Apache Spark
Ocean for Apache Spark Spot Security
Spot Security Case Studies
Case Studies Resource Center
Resource Center Documentation
Documentation News
News Service Status
Service Status What Is CloudOps?
What Is CloudOps? How to Operationalize FinOps
How to Operationalize FinOps Our Story
Our Story The Spot Team
The Spot Team Contact Us
Contact Us Our Values
Our Values Careers
Careers
Lingk.io is a data loading, data pipelines, and integration platform built on top of Apache Spark, serving commercial customers, with expertise in the education sector. Their visual interface makes it easy to load, deduplicate and enrich data from dozens of sources, and promote projects from development to production in a few clicks. They were looking to migrate to reduce their AWS costs, improve their customer experience and streamline operational work for the data team.
By migrating from EMR to Ocean for Apache Spark, Lingk’s customers now enjoy ~2x faster Spark applications, Lingk’s AWS bill has decreased by 65%, and Lingk’s team can spend less time managing their infrastructure to focus on expanding their Spark-based data integration platform!
The Challenge: EMR is hard to manage & expensive
As a data integration platform, Lingk makes it easy for its customers to run Spark jobs, whether it’s for ad-hoc projects or for automatically scheduled production data pipelines, making Apache Spark core to Lingk’s business.
The data engineering team at Lingk had several challenges working with EMR:
- Spark apps would take 40 seconds to start on average, and cause a poor user experience when building data pipelines and integrations.
- EMR required too much infrastructure management for their DevOps team with limited Spark experience.
- The core Spark application was stuck at an earlier version because upgrading Spark to 3.0+ caused unexplained performance regressions.
- High AWS costs for running customers’ pipelines required a new look at autoscaling.
The Solution: Serverless Spark
Ocean for Apache Spark is deployed on a managed Kubernetes cluster (EKS) inside Lingk’s AWS account. Ocean for Apache Spark automatically scales the cluster up-and-down based on load and tunes the Spark configurations based on historical data. Instead of HDFS, S3 is used for intermediate storage, with fast access guaranteed using optimized S3 committers.
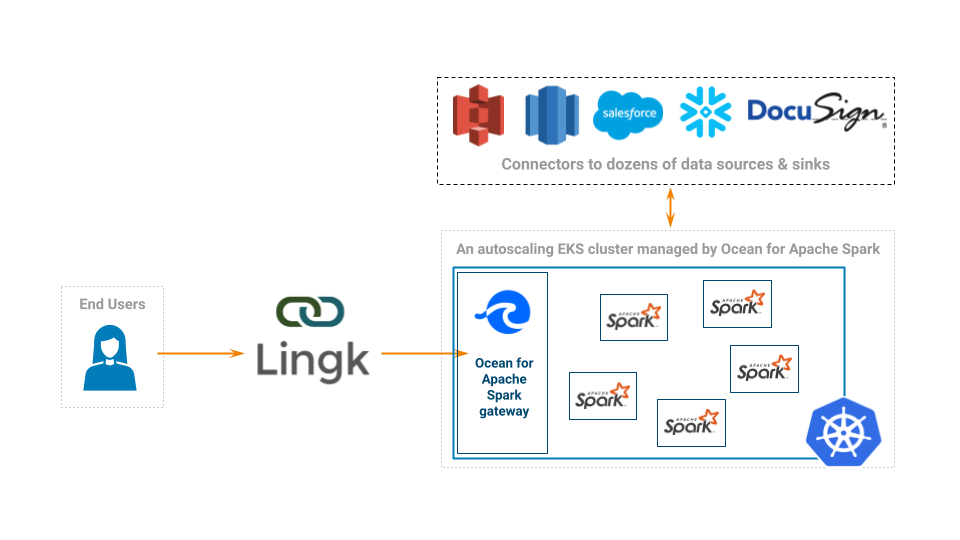
Lingk’s team does not have to manage clusters anymore, they just submit dockerized Spark apps through the Ocean for Apache Spark REST API and enjoy a serverless experience. The team has control over the docker images used by Spark, which brings 3 additional benefits:
- Applications start more quickly – as all dependencies are baked in the Docker image.
- The CI/CD flow is simpler – A Docker image is built automatically when a PR is merged.
- The Docker image includes the Spark distribution itself (there is no global Spark version), which means all applications can efficiently run on the same cluster, and it was easy to gradually upgrade to Spark 3.0.
The automated configuration tuning enabled several performance optimizations:
- Container sizes optimization to maximize bin-packing on (newer generation) instances
- Tuning the number of partitions for optimal parallelism (many jobs suffered from too many small files)
- Dynamic allocation to give additional Spark executors and speed up long-running pipelines significantly (5x speedup for their 99th-percentile longest apps!).
The Results: A big win for end-users, for the team, and for the wallet!
The migration from EMR to Ocean for Apache Spark was a big win:
- In terms of end-user experience, the Spark application startup time was halved, and the average app duration decreased by 40%.
- In terms of costs, the AWS costs were reduced by over 65%. The total cost of ownership for Lingk was reduced by 33%.
Lingk was also able to gradually upgrade Spark to 3.0, which was made easy by the Spark-on-Kubernetes architecture which enabled native dockerization. The team at Lingk can now confidently expand their data integration platform toward new ambitious use cases.
Thanks to the migration, Lingk’s AWS costs decreased by 65%, the application startup time was halved, and the average app duration decreased by 40%.