 Cloud Financial Management (FinOps)
Cloud Financial Management (FinOps) Autoscaling applications
Autoscaling applications Amazon Web Services
Amazon Web Services Big data
Big data Container infrastructure
Container infrastructure Microsoft Azure
Microsoft Azure Reserved commitment management
Reserved commitment management Cloud services for MSPs
Cloud services for MSPs Google Cloud
Google Cloud Spot Overview
Spot Overview About NetApp
About NetApp Elastigroup
Elastigroup Ocean
Ocean Ocean CD
Ocean CD Eco
Eco Ocean for Apache Spark
Ocean for Apache Spark Spot Security
Spot Security Case Studies
Case Studies Resource Center
Resource Center Documentation
Documentation News
News Service Status
Service Status What Is CloudOps?
What Is CloudOps? How to Operationalize FinOps
How to Operationalize FinOps About Us
About Us Contact Us
Contact Us Careers
Careers
 Reading Time: 6 minutes
Reading Time: 6 minutesThis article is jointly written by:
- Spot’s Ocean for Apache Spark team who is bringing a next-generation Spark platform deployed on Kubernetes. Our mission is to make Spark more easy-to-use and cost-efficient, with a focus on data engineering workloads.
- Quantmetry, an AI & Data Consulting firm expert in helping European enterprises adopt technologies like Apache Spark to solve mission critical business goals.
What makes Apache Spark popular?
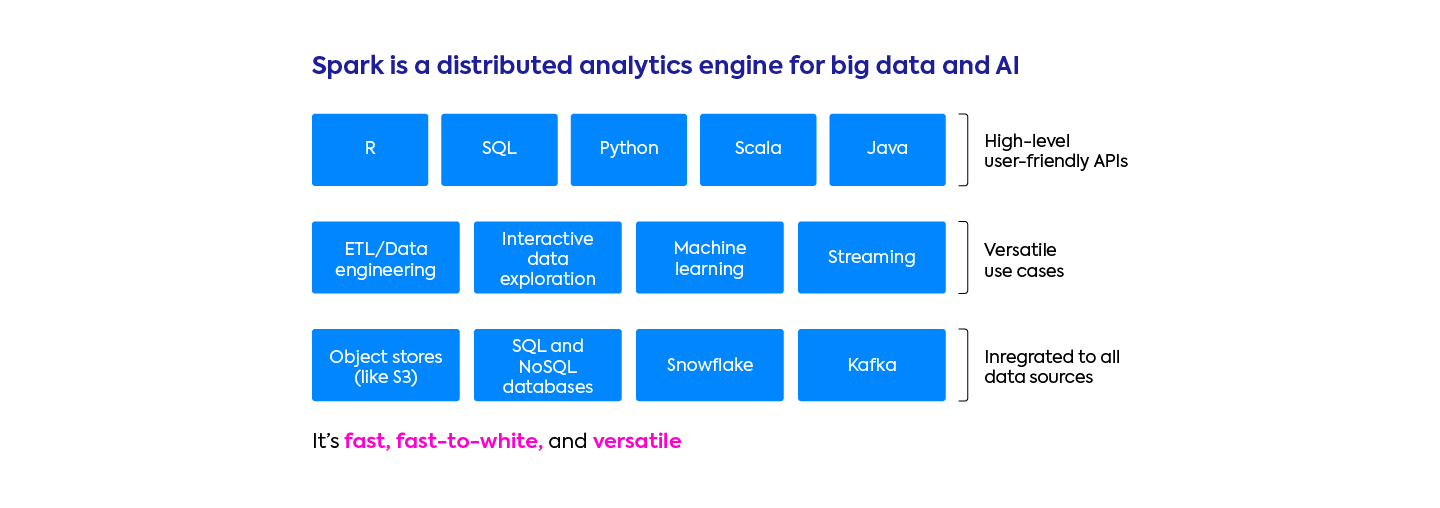
In the data science and data engineering world, Apache Spark is the leading technology for working with large datasets. The Apache Spark developer community is thriving: most companies have already adopted or are in the process of adopting Apache Spark. Apache Spark’s popularity is due to 3 mains reasons:
- It’s fast. It can process large datasets (at the GB, TB or PB scale) thanks to its native parallelization.
- It has APIs in Python (PySpark), Scala/Java, SQL and R. These APIs enable a simple migration from “single-machine” (non-distributed) Python workloads to running at scale with Spark. For example, the Koalas library was recently released, which enables Python developers to easily turn their Pandas code into Spark. The fact that arbitrary Python/Scala code can be executed also gives Spark developers a lot more flexibility than SQL-only frameworks like Redshift and BigQuery.
- It’s very versatile. Apache Spark has connectors for virtually all data storages, and Spark clusters can be deployed in any cloud or on-premise platforms.
What are the top pain points with Apache Spark?
Debugging application code
The first challenge is the fact that it’s hard for Spark beginners to understand how their code is interpreted and distributed by Spark. You need to learn about the intricacies of Spark and get to a certain level of expertise to be able to debug your application when it does not perform as expected (for example, debug a memory error), and to understand and then optimize its speed.
Spark exposes many configurations that are complex for beginners to set. As a result, most Spark developers tend to stick to default settings, without realizing how this can hurt their application stability and performance.
Managing the underlying infrastructure
The second challenge is infrastructure management. What should be the size of our Spark cluster? Which type of virtual machines and disks should I choose? How should we collect and visualize logs and metrics?
These challenges come in two different flavors between on-premise deployments (with Hortonworks, Cloudera, MapR) and cloud deployments (AWS: EMR, GCP: Dataproc, Azure: HDInsight).
- For on-prem deployments, the main challenge is the cost / speed tradeoff on the cluster size. If you oversize your cluster, your costs will snowball and you will suffer from low utilization and overprovisioning resources to your cluster most of the time. If you undersize your cluster, it will not be able to sustain peak workloads, and you will need to implement priority queues to make sure your mission critical workloads are not delayed.
- For cloud deployments, the elasticity of the cloud provider solves this problem as resources can be added or removed on the fly. This also means that costs are unbounded, and it is up to each individual Spark user to appropriately size and configure their applications and make sure that it is stable and cost-efficient. Despite the services being called “managed”, the real burden of management and configuration is still on the data teams using the Spark cluster.
Let’s now go over Spot’s best practices and recommendations to overcome these challenges.
Simplifying Spark Infrastructure Management with a Serverless Approach
Ocean for Spark is a managed Spark platform deployed on a Kubernetes cluster inside our customers’ cloud account. It is available on the 3 big cloud providers (AWS, GCP and Azure) and it is an alternative to platforms like Databricks, Amazon EMR, Google Dataproc, and Azure HDInsight. Jean-Yves – an ex-Databricks engineer, co-founder of Data Mechanics, now product owner for Ocean Spark, explains our 3 key features that implement a serverless approach to Apache Spark.
It’s Dockerized.
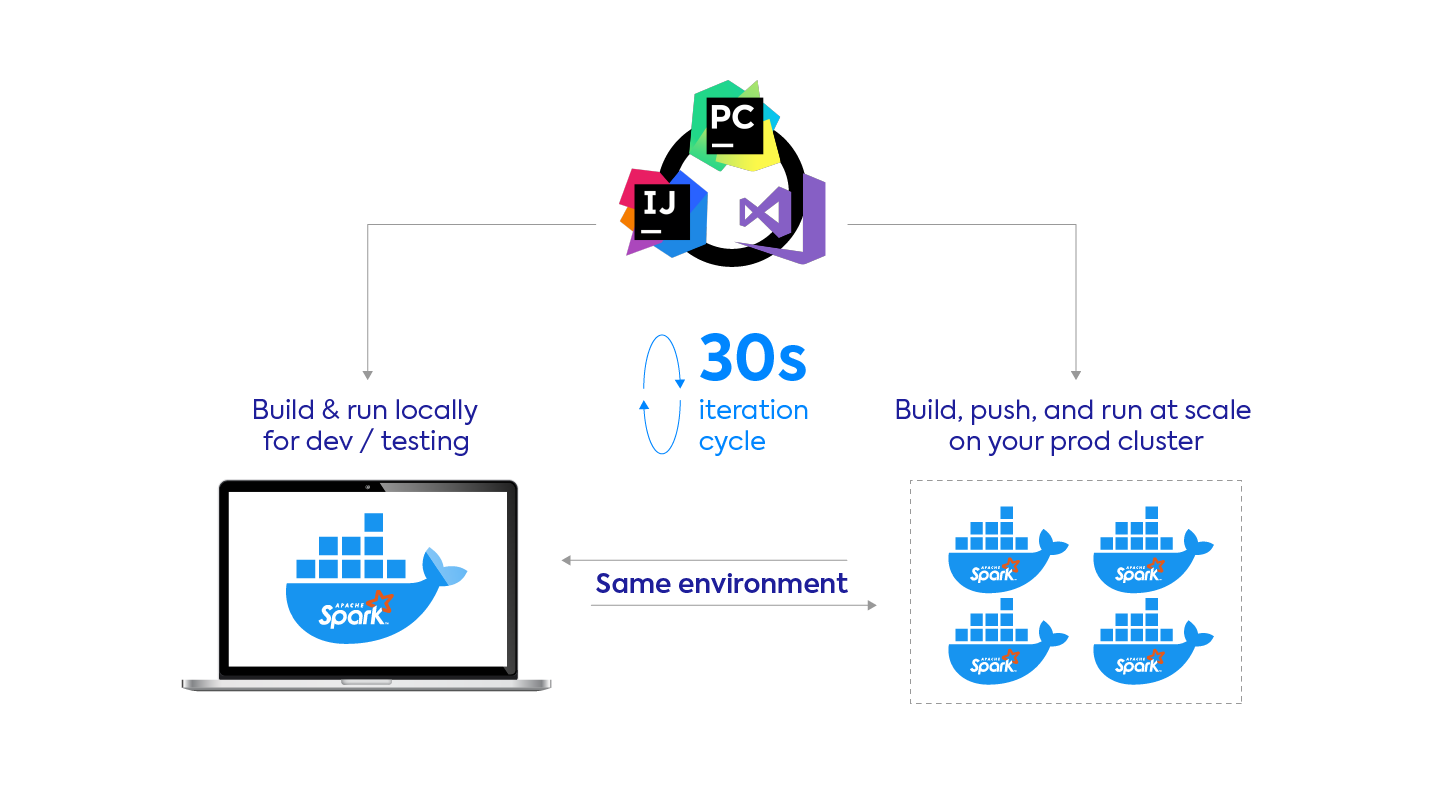
Kubernetes has native support for Docker containers. These containers let you build your dependencies once (on your laptop) and then run your application everywhere in a consistent way: on your laptop, for development and testing; or in the cloud over production data.
Using Docker rather than slow init scripts and runtime dependency downloads will make your Spark applications more cost-efficient and stable. With the proper optimizations, you can speed up your Spark development cycle with Docker such that it takes less than 30 seconds from the time you make a change to your code to the time it is deployed on our platform.
Update (April 2021): We’ve now publicly released our optimized Docker images for Apache Spark (check our DockerHub). They contain all the commonly used data connectors, as well as Spark, Hadoop, Java, Scala, Python, and other libraries – to help get you started with images “that just work, out of the box”!
It’s in autopilot mode.
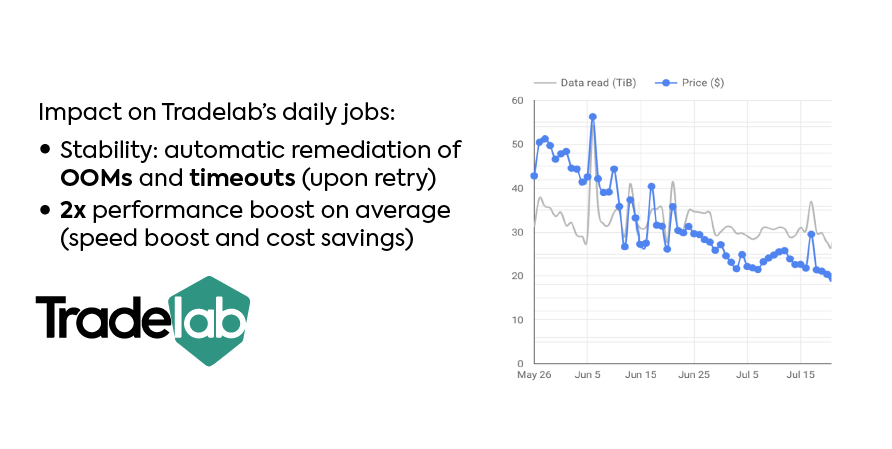
We believe a “managed” Spark platform should do more than simply start virtual machines when you request them. It should actually take the infrastructure management burden from its users. Hence our platform dynamically and automatically adjusts the most important infrastructure parameters and Spark configurations: cluster sizes, type of instance, disk types, level of parallelism, memory management, shuffle configurations, etc. This makes Spark 2x more stable and more cost-efficient, as we illustrated at the 2019 Spark Summit with a customer success story.
It’s priced on actual Spark compute time.
Competing Spark platforms charge a fee based on server uptime (“Using this type of instance for an hour will cost you $0.40”). This fee is due whether the machine is actually used by Spark, or whether it’s just up but not doing anything because you made a configuration mistake.
At Spot, we only charge our customers when their machines are used to run Spark computations, not based on overall server uptime. This gives us an incentive to manage your infrastructure more efficiently and remove wasted compute resources. Book a meeting with us if you’d like us to assess how this could reduce your costs.
The third point is specific to our platform, but the first two recommendations — dockerization and some autopilot features (autoscaling at least) may be available in your Spark platform.
Make Spark more accessible with a new monitoring UI
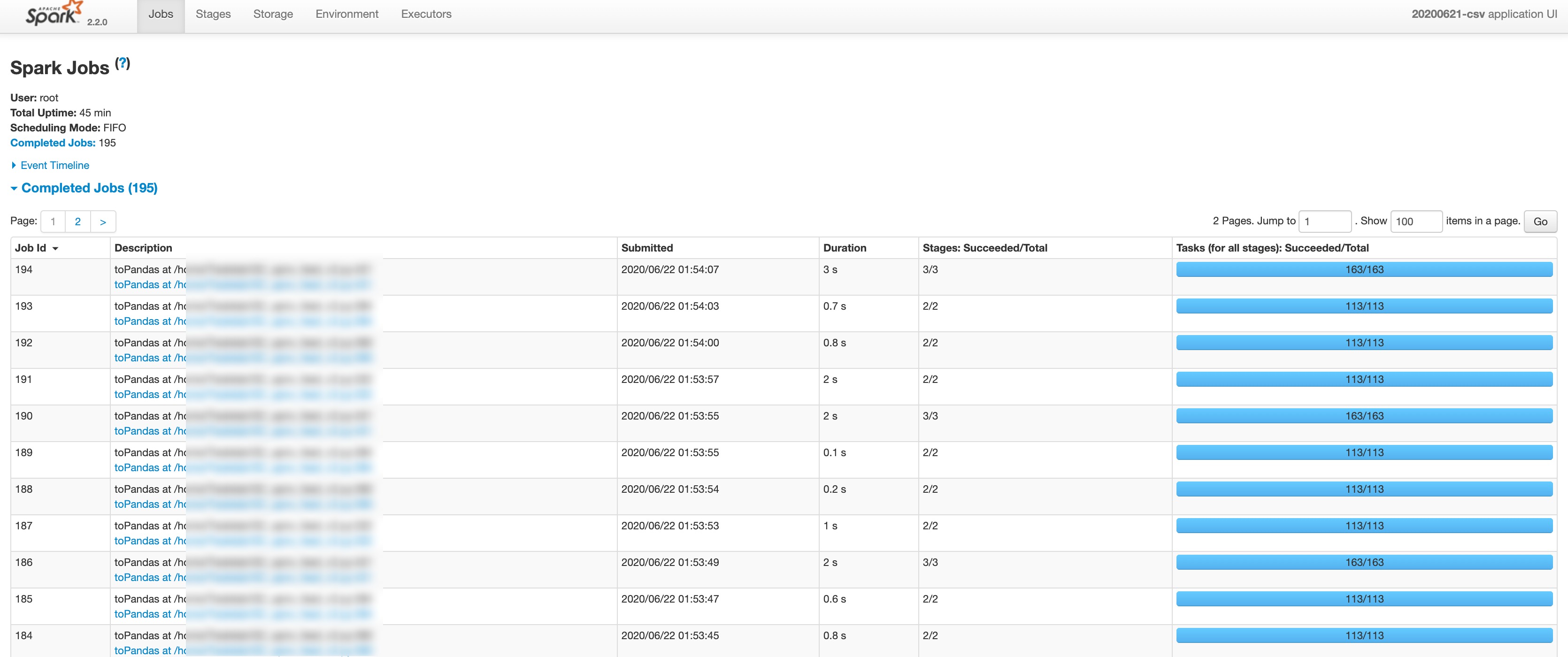
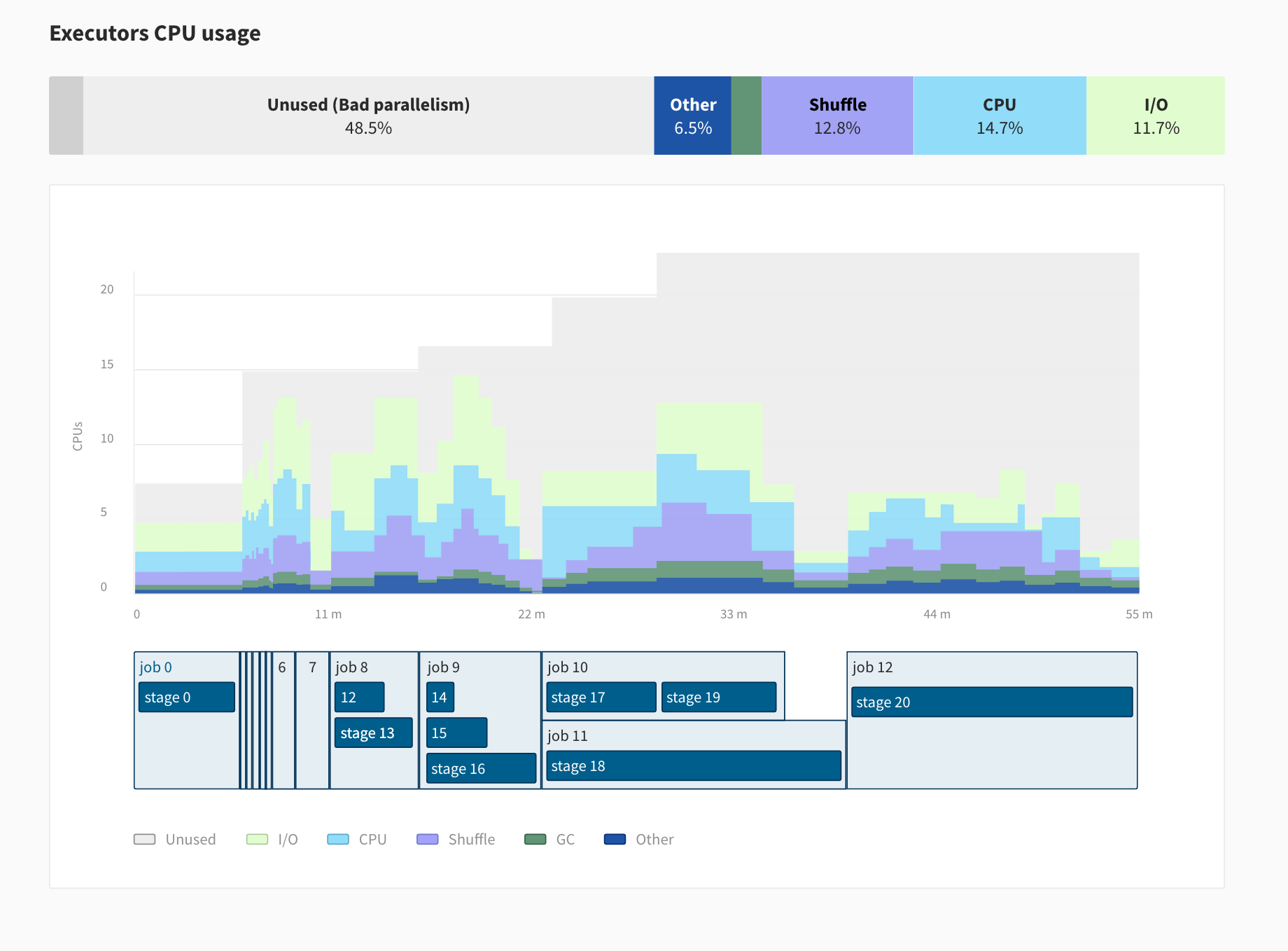
The serverless approach can speed up your iteration cycle by 10x and divide your costs by 3x. But if your Spark code has a bug or if your data isn’t partitioned the right way, it’s still up to the developper to solve this problem. Today the only monitoring tool available to solve these challenges is called the Spark UI (screenshot below), but it’s cumbersome and not intuitive:
- Too much information is displayed. It’s hard to spot where the application spends most of its time and what is the bottleneck.
- It lacks critical metrics around memory usage, cpu usage, I/O.
- The Spark History Server (necessary to access the Spark UI after an application is finished) is hard to set up.
To solve this problem and make Spark more accessible to beginners and experts alike, the Ocean for Spark team is developing a new monitoring tool to replace the Spark UI, Delight. Delight will be made available to the wider Spark community (not just Spot customers) for free. You will be able to install it on any Spark platform (in the cloud or on-premise) by downloading an open-source agent which will run inside the Spark driver and stream metrics to the Ocean for Spark backend.
Here’s a screenshot of what Delight looks like. It consists of an overview screen to help developers get a bird-eye view of their application, with key metrics and high-level recommendations. New metrics around CPU and Memory usage will help Spark developers understand their application resource profile and bottleneck.
Update (April 2021): Delight has been officially released! Sign up for free through our website and check out our github page to install Delight on top of your Spark platform (we support Databricks, EMR, Dataproc, HDInsight, CDH/HDP, open-source distributions, etc).
Conclusion: The Future of Apache Spark
We hope this article has given you concrete recommendations to help you be more successful with Spark, or advice to help you get started! Quantmetry and Spot are available to help you on this journey.
To conclude let’s go over exciting work currently happening within Apache Spark.
- Spark 3.0 (June 2020) has brought 2x performance gains on average through performance optimizations such as Adaptive Query Execution and Partition Pruning. Dynamic allocation (autoscaling) is now available for Spark on Kubernetes. New Pandas UDF and Python type hints also make PySpark development easier.
- Spark 3.1 (December 2020) will declare Spark-on-Kubernetes as officially generally available and production-ready thanks to more stability and performance fixes, hence accelerating the transition from YARN-based platforms to Kubernetes-based platforms (like Ocean for Spark). More performance optimizations are also coming in like filter pushdown for JSON and Avro file formats.