 Cloud Financial Management (FinOps)
Cloud Financial Management (FinOps) Autoscaling applications
Autoscaling applications Amazon Web Services
Amazon Web Services Big data
Big data Container infrastructure
Container infrastructure Microsoft Azure
Microsoft Azure Reserved commitment management
Reserved commitment management Cloud services for MSPs
Cloud services for MSPs Google Cloud
Google Cloud Spot Overview
Spot Overview About NetApp
About NetApp Elastigroup
Elastigroup Ocean
Ocean Ocean CD
Ocean CD Eco
Eco Ocean for Apache Spark
Ocean for Apache Spark Spot Security
Spot Security Case Studies
Case Studies Resource Center
Resource Center Documentation
Documentation News
News Service Status
Service Status What Is CloudOps?
What Is CloudOps? How to Operationalize FinOps
How to Operationalize FinOps About Us
About Us Contact Us
Contact Us Careers
Careers
The Background: The mission of the United Nations Global Platform
Under the governance of the UN Committee of Experts on Big Data and Data Science for Official Statistics (UN-CEBD), the Global Platform has built a cloud-service ecosystem to support international collaboration in the development of Official Statistics using new data sources, including big data, and innovative methods and to help countries measure the Sustainable Development Goals (SDGs) to deliver the 2030 Sustainable Development Agenda.
The Task Team on AIS is a group of participating organisations across the globe made of dozens of statisticians interested in using AIS data (global time-series datasets about vessels’ position and speed) for official statistical and experimental indicators purposes. The Task Team uses the UN Global Platform to store, manage and analyse the AIS data, growing by 300 billion records per year. See an example of their work: Faster indicators of UK economic activity project.
The Challenge: HBase + EMR was hard to manage & expensive
The platform used to rely on an HBase instance for hosting AIS data, and Apache Spark running on the AWS EMR platform for the analysis of this data. The data team at the UN Global Plaform had several challenges with this setup:
- The EMR cluster was oversized (except during peak loads) and its autoscaling capabilities were not satisfactory, leading to high costs.
- The cluster would get unstable when tens of users ran competing queries concurrently.
- The python libraries available to end users were limited as the process to install additional ones was complex.
- Costly to keep years of historical data in an HBase instance
- The complexity of HBase management
The high cost and lack of flexibility of this system prompted the search for a better solution.
The Solution: 70% lower costs and a better user experience with Ocean for Apache Spark
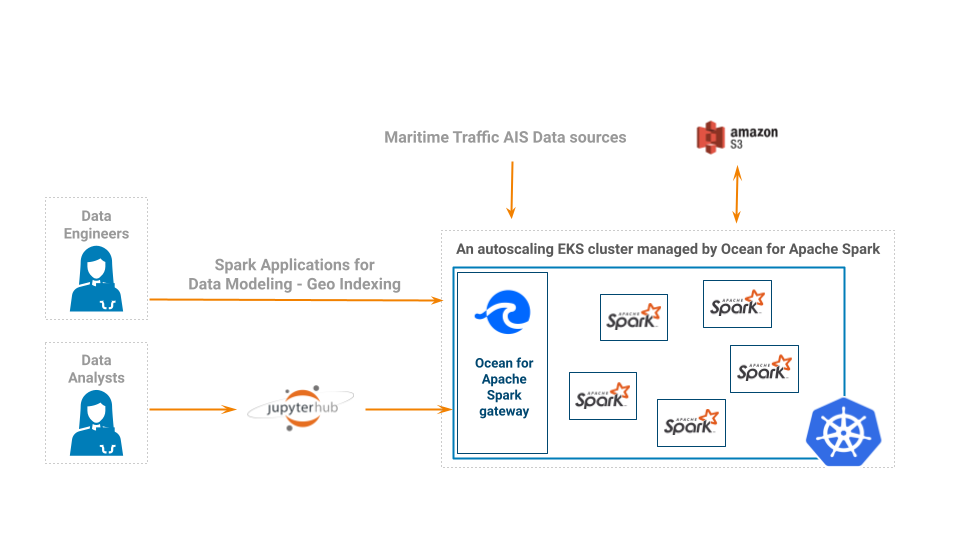
Apache Spark now runs on a Kubernetes (EKS) cluster managed by Ocean for Apache Spark. End-users submit programmatic jobs through the API for batch processing, and connect Jupyter notebooks (hosted on Jupyter Hub) for interactive data exploration.
- Each user gets its own set of ressources (Spark driver, Spark executor) which are isolated from others, and automatically scale up and down based on the load.
- Users can install new libraries in a self-service way and without impacting others by adding them to their docker images The set of libraries that can be supported in the Docker images is virtually infinite, resulting in better analysis and reporting for all needs.
- Ocean for Apache Spark enabled significant cost reductions through fast cluster autoscaling capabilities and additional code performance optimizations.
- Using S3 as the main data source reduced the costs further and provided additional flexibility in storage management, while providing a rich historical depth.