
"The Spark UI is my favorite monitoring tool" — said no one ever.
The Apache Spark UI generates a lot of frustrations. We keep hearing it over and over from Spark beginners and experts alike:
- "It's hard to understand what's going on"
- "Even if there's a critical information, it's buried behind a lot of noisy information that only experts know how to navigate"
- "There's a lot of tribal knowledge involved"
- "The Spark history server is a pain to setup"
So our team had to replace the Spark UI and Spark History Server with something delightful, a free cross-platform and partially open-source tool called Data Mechanics Delight.
Update (April 2021): Delight has been officially released! It works on top of any Spark platform: Databricks, EMR, Dataproc, HDInsight, CDH/HDP, Spark on Kubernetes open-source, Spark-on-Kubernetes operator, open-source spark-submit, etc. Check out our website and github page to get started!
What's wrong with the current Apache Spark UI?

It's hard to get the bird's eye view of what is going on.
- Which jobs/stages took most of the time? How do they match with my code?
- Is there a stability or performance issue that matters?
- What is the bottleneck of my app (I/O bound, CPU bound, Memory bound)?
The Spark UI lacks essential node metrics (CPU, Memory and I/O usage).
- You can go without them, but you'll be walking in the dark. Changing an instance type will be a leap of faith.
- Or you'll need to setup a separate metrics monitoring system: Ganglia, Prometheus + Grafana, StackDriver (GCP), or CloudWatch (AWS).
You'll need to jump back and forth between this monitoring system and the Spark U trying to match the timestamps between the two (usually jumping between UTC and your local timezone, to increase the fun).
The Spark History Server (rendering the Spark UI after an application is finished) is hard to setup.
- You need to persist spark event logs to long-term storage and often run it yourself, incurring costs and maintenance burden.
- It takes a long time to load, and it sometimes crashes.
What does the Data Mechanics Delight UI look like?
A picture is worth a thousand word, so here's a GIF of our prototype:
What is new about it?
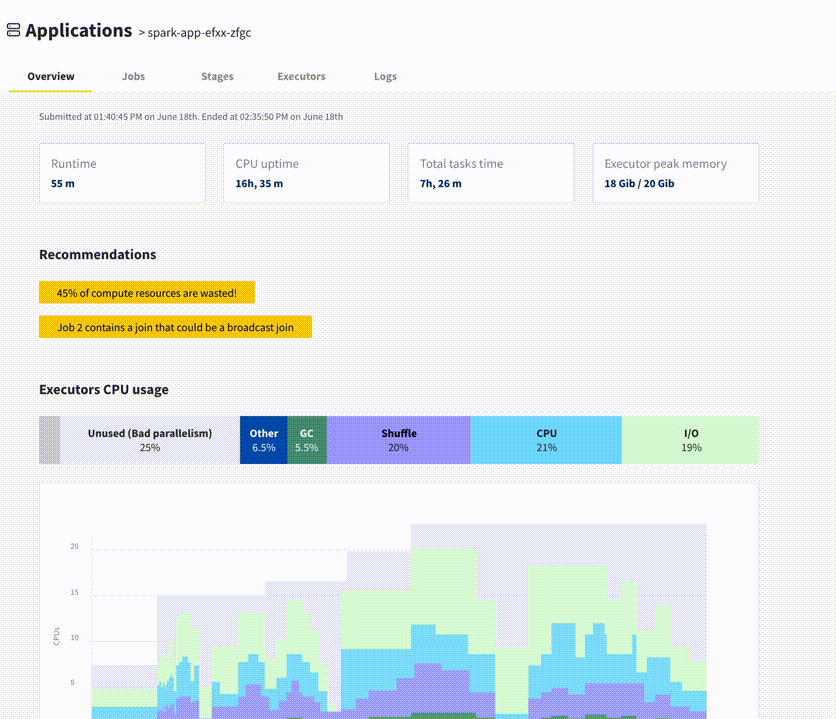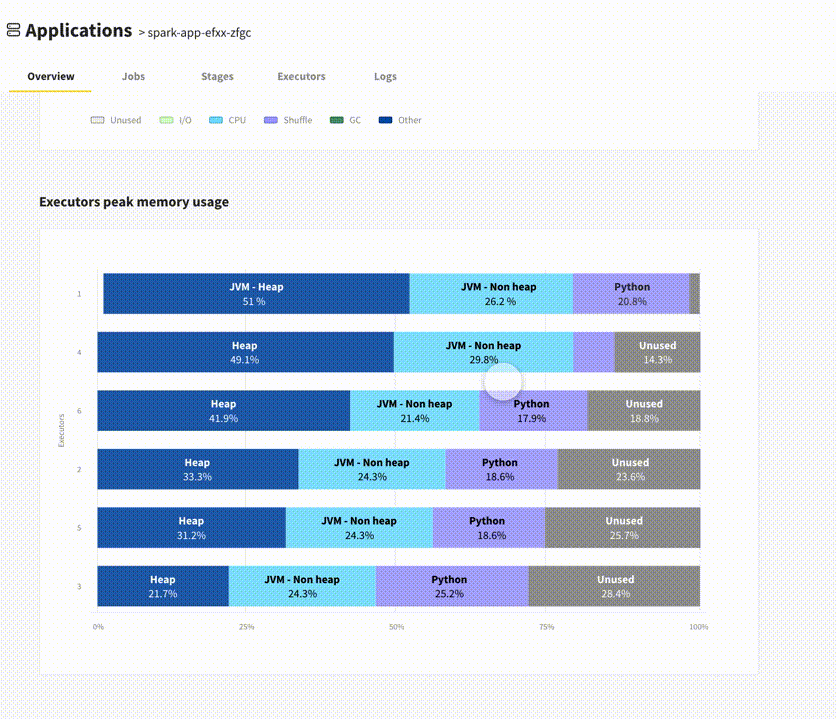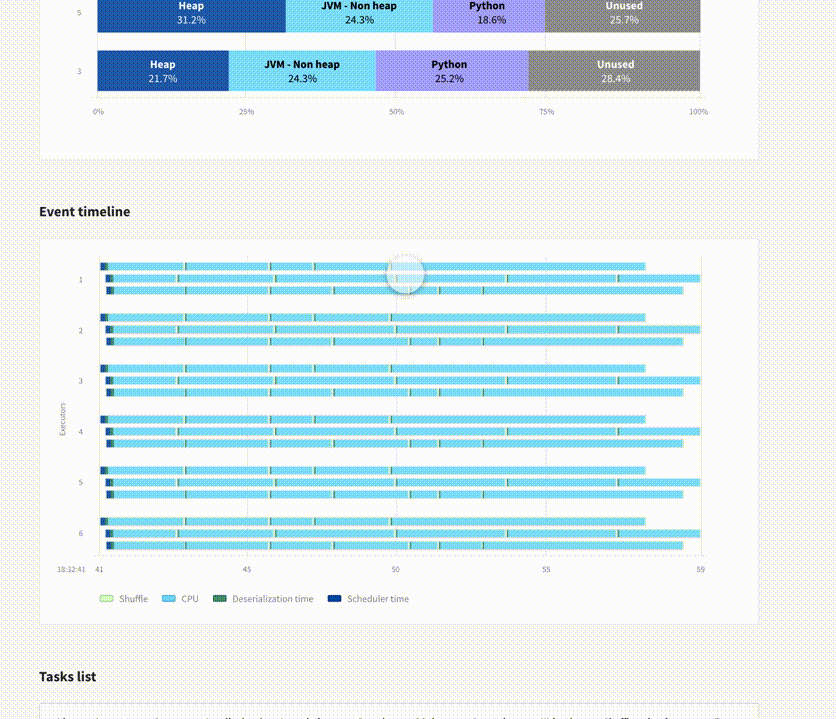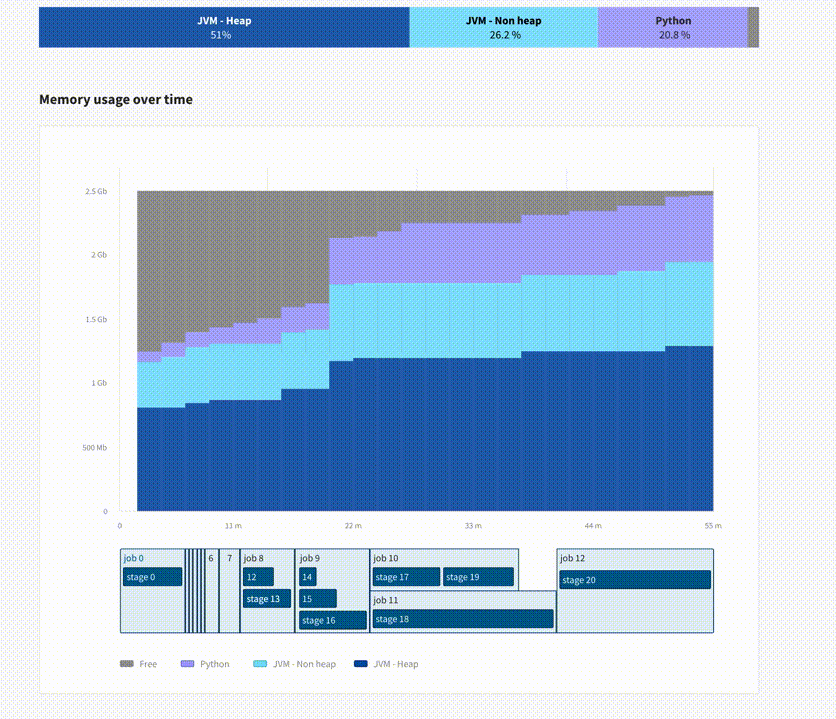
The main screen (overview) has a lot of new information and visuals.
Summary statistics

What was the duration of the app, the amount of resources (CPU uptime) that were used, the duration of all the Spark tasks (should be close to your CPU uptime unless you suffer from bad parallelism or long phases of driver-only work/idleness).
Recommendations

This section pinpoints stability and performance issues at a high-level to help developers address them. Examples:
- "The default number of tasks (200) is too small compared to the number of CPU cores (400) available. Increase spark.sql.shuffle.partitions to 1200."
- "Job 4 suffers from an input data skew. Consider repartitioning your data or salting the partition key".
- "An executor crashed due to an OutOfMemory error in stage 7 with 85% of the memory used by Python, consider increasing the memory available per executor or setting spark.executor.pyspark.memory".
This section builds upon the capability of the Data Mechanics platform to automatically tune infrastructure parameters and Spark configurations (e.g. instance type, memory/cpu allocations, configs for parallelism, shuffle, I/O) for each pipeline running on it based on its history. This high-level feedback will complement the serverless features of the platform by helping developers understand and optimize their application code.
Executors CPU Usage

What were your executor CPU cores doing on average? If there is a lot of unused time, maybe your app is overprovisioned. If they spend a lot of time doing shuffles (all-to-all data communications), it's worth looking if some shuffles can be avoided, or at tuning the performance of the shuffle stages. This screen should let you see quickly if your app is I/O bound or CPU bound, and make smarter infrastructure changes accordingly (e.g. use an instance type with more CPUs or faster disks).
What's great with this screen is that you can visually align this information with the different Spark phases of your app. If most of your app is spent in single shuffle heavy stage, you can spot this in one second, and in a single click dive into the specific stage.
Executors Peak Memory Usage

This screen shows you the memory usage breakdown for each executor when the total memory consumption was at its peak. You'll be immediately able to see if you went close to the memory limit (narrowly avoiding an OutOfMemory error), or if you have plenty of leg room. Data Mechanics Delight gives you the split between the different types of memories used by the JVM and the python memory usage. This data is crucial but as far as we know Spark developers have no easy way to get this today.
Stage and Executor Pages

You can then dive in and find similar information at a finer granularity on a Spark stage page or an executor page. For example, on a specific stage page, you'll see graphs showing the distribution of a metric (e.g. duration or input size) over all the tasks in this stage, so you can immediately visually notice if you suffer from skew. Check the animated GIF for a full tour.
What is NOT new about it?
The Spark UI also has many visuals that work really well. Our goal is not to throw it all away. On the contrary we would like Data Mechanics Delight to contain as much information as the current Spark UI. We plan to reuse many elements, like the tables for the list of jobs, stages, and tasks, the Gantt chart illustrating tasks scheduled across executors within a stage, the DAG views, and more.
How does debugging with Data Mechanics Delight work in practice?
We'll use two concrete scenarios we recently encountered with some of our customers.
A parallelism issue
One of our customer was running an app with 10 executors with 8 CPU cores each, such that the app could run 80 Spark tasks in parallel. But a developer had set the `spark.sql.shuffle.partitions` configuration to 8, such that during shuffles only 8 tasks were generated, meaning 90% of the app resources were unused. This configuration was a mistake (probably set during local development), but the fact is that this critical issue is completely silent in the current Spark UI, unless you know really well where to look for it. In Data Mechanics Delight, the issue would be obvious:

This parallelism example might seem planted, but note that it's more common than you think — it also happens when the default value (200) is too small compared to the total app capacity, or when the input data is incorrectly partitioned (which takes more than a configuration change to fix).
A memory issue
Memory errors are the most common source of crashes in Spark, but they come in different sorts. The JVM can get an OutOfMemory error (meaning the heap got to its maximum size, needed to allocate more space, but even after GC couldn't find any), this can happen for many reasons like an imbalanced shuffle, a high concurrency, or improper use of caching. Another common memory issue is when a Spark executor is killed (by Kubernetes or by YARN) because it exceeded its memory limit. This happens a lot when using PySpark, because the Spark executor will spawn one python process per running task.

Few monitoring tools let you see the breakdown between memory usage by the JVM (heap and non-heap) and Python, and yet this information is crucial for stability. In this screenshot, we can see that the executor with the highest memory usage got very close to the limit.
PySpark users are often in the dark when it comes to monitoring memory usage, and we hope this new interface will be useful to them and avoid the dreaded OOM-kills.
How does Data Mechanics Delight work?
Data Mechanics Delight consists of two main pieces:
- An open-source agent which runs inside your Spark applications. This agent will stream Spark event logs from your Spark application to our backend.
- A closed-source backend consisting of a real-time logs ingestion pipeline, storage services, a web application and an authentication layer to make this secure.
Conclusion: Let's Get Started
Data Mechanics is a cloud-native Spark platform focused on making Spark easy-to-use and cost-effective for data engineers. Learn more about what our platform adds on top of running Spark on Kubernetes the open-source way. One of our core features is the fact that our platform automatically tunes the infrastructure parameters and Spark configurations to make Spark pipelines more stable and efficient.
Data Mechanics Delight complements our platform by giving Spark developers the high-level feedback they need to develop, productionize and maintain stable and performant apps at the application code level — e.g. understand when to use caching, understand when to repartition the input data because you suffer from skew, etc.
Update (April 2021): Delight has been officially released! It works on top of any Spark platform: Databricks, EMR, Dataproc, HDInsight, CDH/HDP, Spark on Kubernetes open-source, Spark-on-Kubernetes operator, open-source spark-submit, etc. Check out our website and github page to get started!

by